GenAI and LLMs, Key Concepts
Embeddings
Embeddings are a way of turning things like words, sentences, or images into lists of numbers (vectors) placed in a multi-dimensional, mathematical space, so that the relative positions of these vectors reflect how the things relate. Similar items land close together, measured by say cosine similarity, and even the directions between them can track relationships like analogies. No single vector means anything on its own. What matters is where each one sits relative to all the others; an arrangement the model learns during training. Using vectors is additionally convenient, because training happens with neural networks, whose natural inputs and outputs are, indeed, vectors (lists of numbers).
Neural Networks
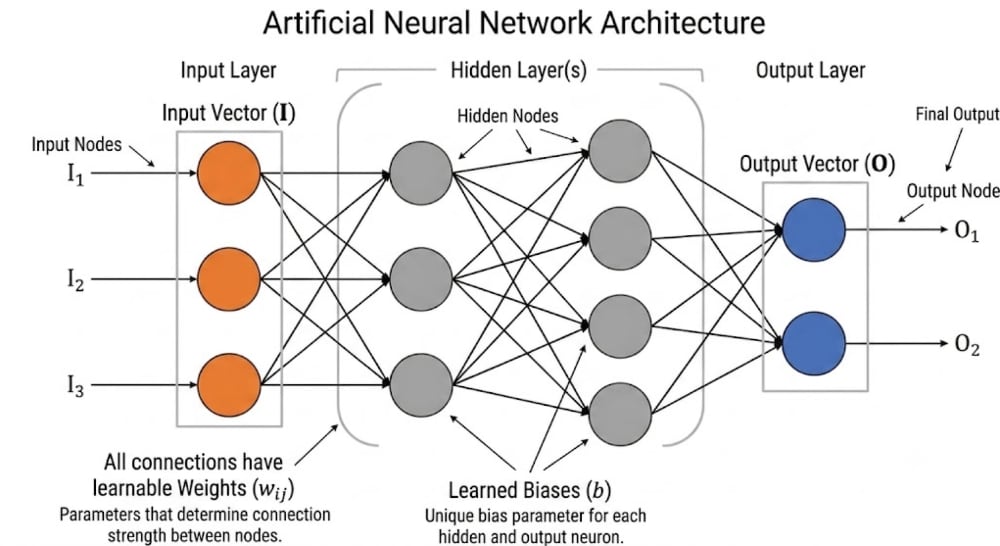
A neural network is a mathematical model that takes an input represented as a list of numbers (a vector) and produces another list of numbers as the output (a probable answer). For example, the image of a handwritten digit becomes a vector of pixel brightness values going in, and the output is a vector of ten numbers (confidence scores), one per possible digit, where the largest score is the network’s guess for an answer. In between, the network multiplies the input vector by large tables of numbers called weights, adds some offsets, and applies a simple squashing step, without which all the layers would collapse into one. This happens in stages (layers), each one transforming one vector into another until the final output vector comes out. The weights are just numbers, and at first they’re random, so the output is garbage. Training is the process of repeatedly showing the network examples with known answers and nudging the weights until the output vectors come out right. Once trained, the weights are fixed, and running the network is just that fixed sequence of multiply-add-squash steps turning an input vector into an answer vector.
Agentic Systems
An agentic system is an AI setup where the model doesn’t just answer in one shot, but works toward a goal over multiple steps: it can decide what to do next, take actions using tools (search the web, run code, call an API, edit a file), see the results of those actions, and adjust its next move based on what came back. The defining trait is the loop. Instead of input-to-answer, it’s decide, act, observe, repeat, until the goal is met or it gives up
Hill-Climbing and Evals
A core techniques of agentic systems. Hill-climbing is the strategy of improving something by making a small change, checking whether it scored better, keeping it if it did and discarding it if it didn’t, then repeating. Usually it is done in loops.
Evals (short for evaluations) are the measurement you climb against. An eval is a defined test that produces a score for how well your system does at something, usually a set of example inputs paired with a way to judge the outputs. For a digit classifier, the eval might be 10,000 labeled images and the score is the percentage it gets right. For a language model, an eval might be a batch of questions plus a rubric or an automated grader checking the answers.
LangChain
LangChain is an open-source library of wrappers and glue code. Its real function is to give you one common interface over things that otherwise have different APIs: swap OpenAI for Anthropic without rewriting your calls, plug in a vector database for retrieval, attach a tool, stitch a few of these steps into a sequence.
LangGraph
LangGraph is an open-source library for controlling flow when the work isn’t a straight line. You define your application as a graph: nodes are steps (call a model, run a tool, check a condition), edges decide what runs next, and the graph can loop back, branch, and carry state from one step to the next. Concretely it’s a state machine for LLM apps. This is the part that’s actually useful for agents, because an agent’s “decide, act, observe, repeat” loop is naturally a cycle, and plain sequential chains can’t express a cycle cleanly. If you’re building something with loops, retries, branching, or a human approval step in the middle, this is the layer that earns its place. If your flow is just A then B then C, you don’t need it.
LangSmith
LangSmith is an observability and evals product, from the makers of LangGraph and LangChain. Importantly, however, unlike the other two it’s a paid hosted service, not an open-source library. Its job is to record what your LLM app actually did: every model call, the exact prompt sent, the response, token counts, latency, cost, and the full trace of a multi-step run so you can see where it went wrong. On top of that logging it lets you build eval datasets (save real inputs and expected outputs, run your system against them, score the results) and track whether a change made things better or worse across versions. This is the one most people find immediately worth it, because “I can finally see the exact prompt that got sent and what came back” solves the single most annoying problem with the other two. It works with LangChain and LangGraph but doesn’t require them; you can point it at a plain API-based app too.
An open-source alternative many people end-up with is Langfuse