The Whole Truth About Embedding of Dependencies in Microservices
As the year counts-down its remaining months, we can safely assume that the 2015 will go down in the annals of software engineering as: The Year of the Rise of Microservices. Throughout 2015, it has been next to impossible to attend a tech conference or have a conversation with a person in the field, without the subject of Microservices rearing its curious head.
Ironically, as much as everybody is raving about Microservices, and despite what Wikipedia would have you believe, there isn’t even a single, formal definition of Microservices that people can agree to. And yet we all drank the Kool-Aid, and yet we all listened in awe to the fascinating Microservices success stories; some of us even getting our own hands “dirty” and developing our own success stories of the field. Exciting!
What Is This Thing Called Microservices?
To me, Microservices is an architectural style that designs a complex system as a distributed network of interacting, specialized, independently-deployable web APIs, which we call “Microservices”.
The Microservices architectural style has clear similarities to what many consider its parent style: Service-Oriented Architecture (SOA), but it would be a grave mistake to declare the two identical.
SOA and Microservices are very vividly the children of their respective times. SOA had its heyday during the rise of the Enterprise Software movement: when Enterprise Service Busses (ESBs) ruled supreme and the markets were flooded with sophisticated, proprietary vendor tools to help Enterprise Architects manage the complexity.
Microservices style is a child of a very different era: the era of agile software development and DevOps. The era in which “supreme ruling” is shunned at, considered a single point of failure (SPOF) and a strong preference is given to many equal-right teams/services coming together, usually: independently, in achieving a shared goal. The role of an architect is changing to that of a facilitator, rather than a [benevolent] dictator.
Decentralized Data Storage
The property of being “independently deployable” is the hallmark of a properly designed microservice. Most of everything else is either the consequence of this key property or a requirement to achieve it.
We can wrap our legacy Java application inside a Docker container, we can “break it up” into a set of WAR files, but if we don’t have Independent Deployability, then we are just fooling ourselves. A litmus test I use asks: “If your Microservices-designed, complex application is hosted at Amazon Web Services, can you take an arbitrary number of your microservices and move them to Google Cloud, Azure, Rackspace etc. (substitute with your favorite cloud here), without changing a single line of code? Will your overall application still be functional and usable?” It is important the answer to this question to be an unequivocal “yes”.
Independent Deployability is tricky because it seemingly requires decentralized data storage: when you move Microservice Foo from AWS to Google Cloud, you need to be able to move its data storage, as well, without affecting any other microservice. Yet, for decades we have designed our architectures with centralized data storage:
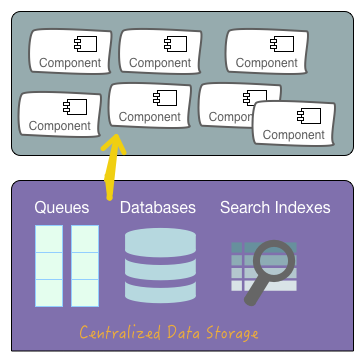
Centralized data storage was convenient: it allowed dedicated, specialized teams (DBAs, sysadmins) to maintain and fine-tune these complex systems, obscuring the complexity away from the developers.
You will often hear people advocate for having microservices independently embed all their dependencies, in order to achieve Independent Deployability. The idea is that if every microservice manages and embeds its database, key-value store, search index, queue etc. then moving this microservice anywhere becomes trivial. This is what such deployment would look like:
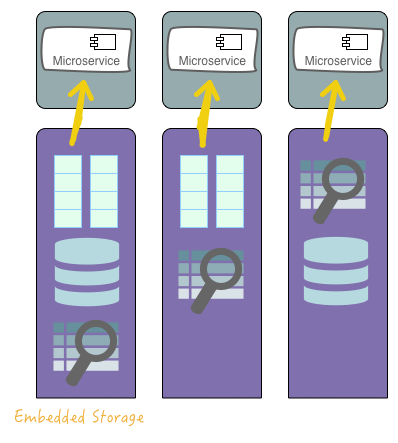
The postulate of wholesale embedding of [data storage] dependencies looks beautiful, on its surface, but unfortunately it is extremely non-practical (or: impossible) for all but the simplest cases. It is quite obvious that you will have very hard time embedding entire Cassandra, Oracle or ElasticSearch clusters in each and every microservice you develop. Especially if you are far down the Microservices journey and possibly have hundreds of microservices. This is just not doable. Neither is it necessary.
The Whole Truth About Dependencies
Microservices can be scary at times. It is natural for Microservices to feel unfamiliar, confusing or complicated, because it is new and we are all still learning it. What is helpful, however is keeping the main goal in mind, at all times, and re-aligning our beliefs accordingly. Here’s the core goal:
We build complex systems with a Microservices architecture, because we want to induce the property of independent development- and deployability of sub-components the complex system is comprised of. Everything else is secondary.
As a Microservice, I don’t have to carry-along every single dependency (such as: data storage system) in order to be mobile and freely move across the data centers (remember our Litmus Test?).
In my current job, I travel a lot for work. I’ve acquired important tips for doing it efficiently that I was completely indifferent to, during my previous life of a casual traveller. As any frequent traveller will tell you: the most important rule for mobility is: keeping your luggage light. You don’t have to pack everything you may possibly need yourself. Nobody packs showerheads and towels on a business trip: you know you will find those at the hotel. Likewise, the trick to a Microservice mobility is not packing everything in, but ensuring that the deployment destination provides heavy assets, such as: database clusters, in a usable form. And that the microservice is written in a way that it can use those assets.
There is one caveat: data-sharing between microservices is still evil. Sharing data creates tight coupling between microservices, which will kill their mobility. I’ve spoken about various techniques to avoid data sharing in a Microservices architecture. However, sharing a database cluster is absolutely OK, given that each microservice only accesses isolated, namespaced portions of it. Following is a diagram showing what a proper, sophisticated Microservices deployment can look in practice:
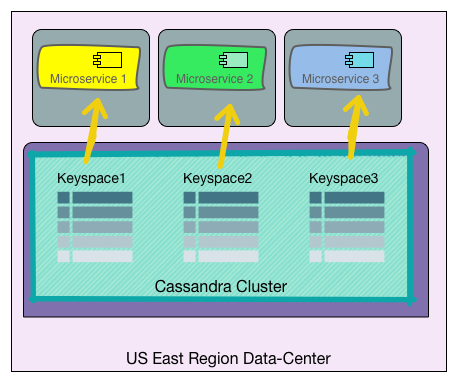
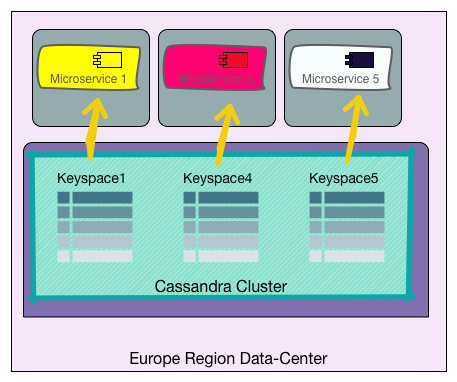
If we decide to move Microservice1 to another data-center, it will expect that the new data-center also has a functioning Cassandra cluster with compatible version (in our earlier metaphor: the destination hotel provides towels) but it will find a way to move its slice of data and won’t depend on existence or state of any other microservice, at the destination:
In Summary
Microservices do not have to “travel” heavy and pack everything they may possibly require. In complicated cases it is OK to have some reasonable expectations about the destination environment, especially when it comes to data storage capabilities.
The most important question we need to ask, when deciding embedding dependencies vs. “expecting” traits in an environment is: will our decision increase or decrease mobility? Our goal is to maximize deployment mobility of a microservice, that may mean different things in different contexts.