Human Identity and the IoT 'Jungle'
A transcript of the talk given at the Cloud Identity Summit
We live in interesting times.

There used to be a popular saying that a single issue of New York Times contains more information than what the average 17th-century person encountered in their entire lifetime. Of course, this was back when New York Times was just a printed newspaper. Now most news break online, and it’s pretty much a continuous stream of information that never stops or takes a break.

The global informational overload, that we are constantly exposed to, can be overwhelming. It’s only natural that sometimes we wish we lived in simpler, less turbulent times. We wish we could just disconnect.
The explosive surge of available data is not all evil, however.

It also brings us unprecedented feeling of global connectedness. We’ve never felt more connected to the rest of the world than we do now.
Technology, computers and the Internet have brought us closer together than ever before. We now take it for granted that you can be pretty much anywhere in the world, yet: get a real-time, front-row view of the breaking news half-way around the globe.
Things are only going to get more interesting…
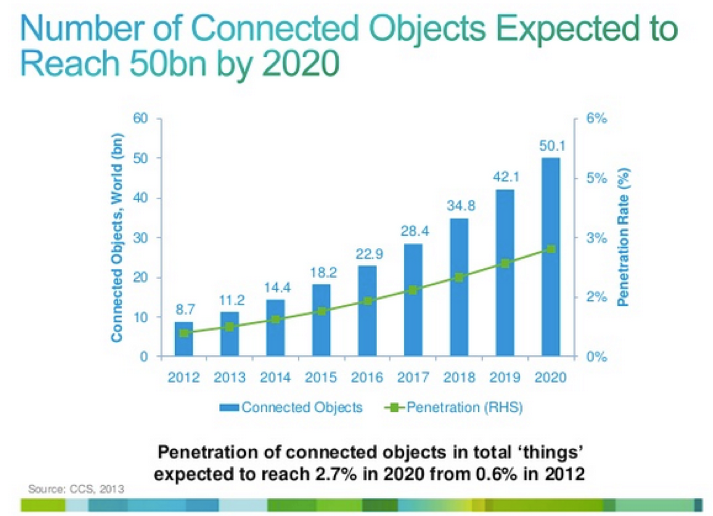
According to Cisco, in 2013, 80 “things” were connecting to the Internet per second. In 2014, we expect that number to reach 100 per second, and by 2020, more than 250 things will connect each second.
Adding-up this growth, we’re expected to have whopping 50Bn connected devices by 2020. That’s 7 connected devices per every human on the planet!
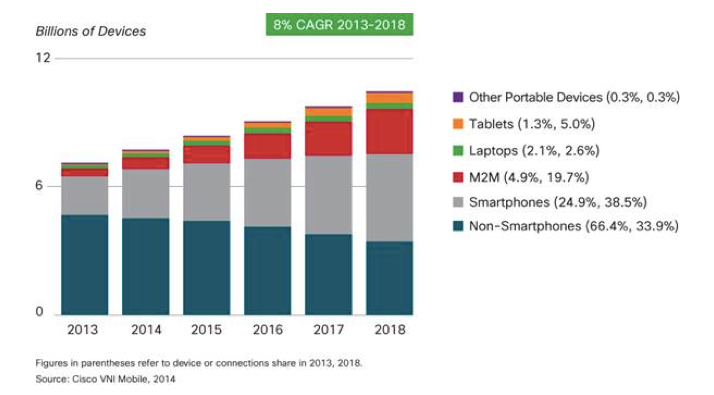
Moreover, out of all connected devices, the highest growth comes on part of smart devices that surround us all the time: smartphones, wearables, connected cars, connected TVs, things like that.

The “wilderness” of the 50 billion connected devices can be intimidating. Candidly, it can be really scary.
And yet, I don’t see too many scared faces around me. What I see is a lot of excitement. I see people who want to take the opportunities of the forthcoming Internet of Things head-on. These are interesting, exciting people. The people involved in the Internet of Things revolution are phenomenally passionate about what they are building. It’s incredibly inspiring to be around people like that, who are pursuing The Future, as their full-time job.

Despite all the excitement and the rush, sometimes we have to step back and make sure that we are not doing something silly.
As we are entering a substantially different environment, we need to make sure that what we do still makes sense.

For decades now, we, computer programmers, have borrowed, copied and imitated the terminology and mannerisms of civil engineers. We even call ourselves “engineers”.
But truth be told, “software engineering” was never really like the architecture of buildings or bridges. In the “real” architecture the cost of a mistake is sky-high: if you make a mistake — a buildings will collapse, bridges will sink. In software engineering the cost of a “mistake” was always significantly lower: the predominant philosophy taught us to “just ship it” — we can fix mistakes, later, relatively cheaply.
With the software world starting to deal with increasingly distributed eco-systems the cost of making a mistake, the cost of a sloppy architecture is rising rapidly.
To address the business needs of mobile-centric, Internet-of-things-oriented world, which we are entering, we need to design our systems with APIs first. Hundreds, thousands, potentially millions of apps use our APIs and we can’t really change them at any time, without breaking a lot of clients.
Welcome to the world of real architecture! The one in which our design decisions have long-lasting effects.

Internet of Things is a complex, highly distributed eco-system. In some ways it is chaotic by design. And yet, however complex, systems we build must just work. When we connect to the web crucial things in our lives, such as our cars and our homes, the allowed margin of error is zero.
I want to share with you three fundamental things that I believe are key to building bullet-proof architectures for the new, highly distributed reality of the Internet of Things.

The most scalable, most distributed system humankind has ever created is: world wide web. We can learn a lot from its design. Better yet, very smart people, have already spent years analyzing what makes web’s architecture work.
The key to the scalability, robustness and long-term relevance of web’s architecture is: Hypermedia.
Hypermedia is the matter of which the World Wide Web is made. Much like physical world is built of interacting elementary particles (Bosons and Fermions), the web is essentially the universe of myriad of interacting hypermedia documents.
“Hypermedia” sounds alien and intimidating. What is Hypermedia? It’s a type of content that not only carries data but also links to other documents and can be interacted with.
Most of you are already familiar with one Hypermedia type: HTML.
We take HTML for granted but HTML is really special. It’s just a handful of tags, but the wealth of creative user-interfaces and user experiences that people are able to build with HTML is truly astounding. You have a handful of simple rules and you get enormous creativity. That’s magical. That’s the kind of thing you need when you are building something revolutionary.
However HTML, as a hypermedia type, was designed for human-centric web, for websites, for rending of content.
In the APIs that we build for the Internet of Things, we will need to marshal structured data around. HTML isn’t ideal for this.

There are however, other hypermedia types that were designed for that very purpose: UBER, Siren, HAL, JSON API… They can play as much of crucial role for IoT as HTML did for the web.

In order to build truly interconnected system for the Internet of Things, it isn’t enough to just build APIs first, or to just use Hypermedia. We need to use both of these tools to create something I call: Linked APIs.
Linked APIs are a new breed of APIs that fix a significant flaw with the current generation of APIs.
The problem with the current APIs is that: most APIs are, at best, creating narrow windows into solid walls surrounding the silo-ed data islands. Even the most well-known and large APIs – such as those provided by Twitter, Facebook or Google – only operate on the data that is within their own databases.
To take Twitter as the example: there is a lot that you can do with their public API; but in the end all of the created content always resides on Twitter’s servers.
In that sense, current APIs create isolated, guarded data islands in the universe of the web. Which is very “anti-web” — the web was created in the spirit of decentralized equal participation. On the web, everybody publishes everywhere, owns their data, and then we have ways to reach that data through hyperlinks, RSS feeds, activity streams, Google search and other methods. APIs have not really reached that stage of maturity yet. APIs are highly centralized, in terms of data storage, and virtually none of them ever link to other APIs.
We need APIs that link to each other. Hyperlinks were essential for the growth of human web. They are equally essential for the Internet of Things ahead of us.

We have all gotten very frivolous with identity and privacy on the web. Web was created as a very privacy-conscious platform. Unfortunately, lately a lot of services started insisting on “real identity”. One of the very unfortunate examples of this was when about a year ago Google+ pulled plug on requiring real identity across all Google services and unifying identity across all of its services. This was a huge privacy violation.
As I was preparing for this talk, just several days ago, I read that Google has reversed its decision and is not insisting on real identity anymore. I want to sincerely thank Google for this decision.
Couple of months ago I was at Computers, Freedom and Privacy conference in Virginia. If you aren’t familiar with it, it’s a very traditional conference that has been going for 20 years now and is organized by Association for Computing Machinery. I met a lot of very interesting people at the conference, including some of the most prominent privacy and freedom advocates.
We unfortunately often forget that web is a #1 platform for people who fight for human rights, freedom and online privacy. Web isn’t exclusively populated by teenagers, you know. When large corporations ignore privacy and expose identity of its users, they could be putting people’s lives at risk. There’s unfortunately a lot of harassment going on, on the web. Very often, safety of people depends on their ability to remain anonymous.
It is also not just a matter of safety and security. By insisting on single, so-called “real” identity we are ignoring how life around us actually works.
Real people, even real things in life, don’t have single identity. I certainly have multiple identities depending on the context. It is different depending what I am doing and where I am. My identity for my colleagues at work is different from my identity for my family or for my friends. The properties of my identity that are relevant at a conference, isn’t necessarily what my family cares about when they thinks of me.
We have multiple identities. Software engineers often ignore this. We have gotten too comfortable with this model of there’s authentication and then there’s authorization. The reality is that there’s also an Identity Service in between. Authentication should only have the responsibility of validating if the service can trust my responses. It’s not Authentication layer’s responsibility to assign a user an identity. Unfortunately this is how things are done very often.
Here’s a familiar example of conflating authentication with identity.
I like Google very much and I use Google services a lot. I actually use Gmail for my personal needs, I also use it for couple of projects under a vanity domain. I also used to have a work Google account. The way Gmail works, these are all different accounts. I actually have multiple accounts, even though I am one person. My identity is conflated with the task of authenticating me. And despite the fact that Google has improved multiple-account support over the years, this system still doesn’t work well at all. I constantly have problems switching between accounts, especially while using two-factor auth.
This is unnecessary. I would be perfectly fine with having single authentication mechanism for all my “accounts” and then choosing identity separately depending on what I am doing.
We are often doing things in a wrong way when it comes to Identity on the web and with 50B things joining the arena, with invariably many more contexts in which we will need to use our identity and authenticate ourselves, things are going to get exponentially more confusing.
We need to build things that make sense, that don’t contradict the reality and that respect our privacy and safety. Sooner we do this, more ready we will be for the Internet of things. And until we do it, there’s no sense rushing into things.
Thank you.